
티스토리 뷰
[Elasticsearch 적용기] #2 Elasticsearch 검색 정확도 높이기: Nori와 Edge n-gram을 활용한 검색 최적화
chaewonni 2025. 3. 14. 01:181. 기존 코드 문제 발생 (첫 번째 문제)
https://programming-tree.tistory.com/145
Spring에서 Elasticsearch로 검색 성능 최적화하기
1. Elasticsearch가 LIKE 검색보다 나은 이유기존 RDBMS에서는 문자열 검색을 위해 LIKE '%검색어%'를 자주 사용한다. 그러나 이 방식에는 다음과 같은 문제가 있다.오타 허용 불가사용자가 "강아지" 대신
programming-tree.tistory.com
저번 글을 쓸 때만 해도 nori와 n-gram이 없어도 되지 않을까 생각했다. 한국어 검색이라고 해도 단순 standard analyzer와 Fuzzy 정도로 충분하지 않을까 싶었다. 그런데 막상 여러 데이터를 예로 들어 테스트해보니, 예를 들어
“강아지잠옷”이 "강", "강아", “강아지”.....로는 검색되어도, “잠옷” 키워드로는 검색이 안 되는 문제가 나타났다.
그러다 보니 결국 한국어 형태소 분석을 위한 nori와 부분 검색을 강화해주는 Edge n-gram 설정이 필요하다는 결론에 이르렀다.
따라서 이 글에서는 nori + n-gram 적용 후 발생한 문제와 해결 과정을 공유해보려 한다!
2. Nori와 n-gram, 그리고 Edge n-gram
먼저, 검색 성능을 최적화하기 위해 고려했던 nori, n-gram, Edge n-gram의 개념과 차이를 정리해보자면,
2.1 Nori Analyzer
- 한국어 형태소 분석을 전문적으로 지원하는 Elasticsearch의 한국어 전용 분석기다.
- 단순한 문자 단위 토큰화가 아니라 형태소 단위로 나누어 보다 정교한 검색을 가능하게 한다.
- 예를 들어, "강아지잠옷"이라는 단어를 Nori Analyzer로 분석하면 "강아지잠옷" → ["강아지", "잠옷"] 이와 같이 형태소를 분리한다.
Nori Analyzer의 장점은 단순한 글자 조합이 아니라 실제 의미를 분석하여 검색 가능하도록 해준다는 점이다.
- "강아지잠옷"을 검색할 때 "강아지" 또는 "잠옷"으로도 검색이 가능해진다.
- "강아지의 잠옷"과 같이 조사(의, 가, 는 등)가 포함되어도 올바르게 검색된다.
2.2 n-gram Analyzer
- n-gram은 텍스트를 연속된 작은 단위(gram)로 분할하여 검색 가능성을 높이는 방식이다.
- 이 방법을 사용하면, 단어 중간이나 끝부분을 입력해도 검색이 가능해진다. 예를 들어,
- "강아지잠옷"을 2-gram으로 분할하면:
["강아", "아지", "지잠", "잠옷"]
- 1-gram으로 분할하면:
이렇게 하면 한 글자씩 검색이 가능하지만, 너무 많은 조합이 생성되어 DB 용량이 급격히 증가하는 문제가 발생한다.["강", "아", "지", "잠", "옷"]위와 같이 분할이 된다.
N-gram 장점
- 단어의 어떤 위치에서든 검색이 가능하기 때문에 검색 범위를 넓힐 수 있다.
- 사용자가 "잠옷"이라고만 입력해도 "강아지잠옷"을 검색할 수 있다.
N-gram 단점
- 너무 잘게 분리되면 인덱스 크기가 급격히 증가한다.
- "강아지잠옷"을 1-gram, 2-gram, 3-gram 등으로 저장하면 데이터가 기하급수적으로 커지면서 성능 이슈 발생 가능하다.
- 의미 없는 검색 결과까지 포함될 위험이 있다. 예를 들어, "지잠" 같은 의미 없는 조합이 검색될 수도 있다.
그 결과 선택하게 된 것이 바로 Edge n-gram 이다.
2.3 Edge n-gram Analyzer
- Edge n-gram은 n-gram의 한 종류로, 단어의 앞부분(접두사)만 저장하는 방식이다.
- 즉, 단어의 중간이나 끝이 아니라 앞에서부터 일정 길이까지의 문자 조합만 생성된다.
- 이 방식은 자동완성(autocomplete)이나 접두사 검색을 지원하는 데 효과적이다.
예를 들어 (min_gram = 2, max_gram = 5 기준) 이라고 했을 때,
- "강아지잠옷"을 Edge n-gram으로 분할하면:
["강아", "강아지", "강아지잠", "강아지잠옷"]
- "강아"만 입력해도 "강아지잠옷"을 검색할 수 있다.
- "잠옷"만 입력했을 때 "강아지잠옷"을 찾을 수 없다는 한계가 있다. -> 하지만 이는 위의 Nori Analyzer로 해결
Edge n-gram의 장점
- 자동완성 및 접두사 검색 최적화 → 검색 입력이 많아질수록 정확도가 향상된다.
- 일반 n-gram보다 저장 용량이 훨씬 적음 → 중간 문자까지 포함하는 일반 n-gram보다 필요한 부분만 저장하여 효율적이다.
Edge n-gram의 단점
- 단어 앞부분이 일치하는 경우에만 검색이 가능하다.
- "잠옷"만 입력했을 때 "강아지잠옷"이 검색되지 않는다. -> 하지만 위의 Nori Analyzer를 함께 사용하기 때문에 이 문제를 보완할 수 있다.
2.4 Nori + Edge n-gram 조합 선택
결국 나는 Nori Analyzer와 Edge n-gram을 조합하여 사용하는 것을 선택했다.
그 이유는,
- Nori Analyzer는 단어를 의미 단위로 분리하여 검색 정확도를 높인다.
- Edge n-gram은 부분 검색 및 자동완성을 지원하면서도 인덱스 크기를 최소화한다.
- 일반 n-gram을 사용하지 않은 이유는 DB 용량 증가, 성능 저하, 불필요한 검색 결과 증가 때문.
- 두 가지를 조합하면 "강아지잠옷"이라는 단어에서 "강아지", "잠옷"으로 검색할 수도 있고,
"강아", "강아지잠" 등 접두사 검색도 가능하다.
결과적으로, Nori + Edge n-gram 조합이 한국어 검색 성능을 최적화하면서도 인덱스 크기를 최소화하는 최적의 선택이라고 생각하였다.
3. 적용 방법과 첫 번째 문제 해결
3.1 인덱스 설정
curl -X PUT "<http://localhost:9200/lost_item>" -H "Content-Type: application/json" -d '
{
"settings": {
"analysis": {
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 5,
"token_chars": ["letter", "digit", "whitespace"]
},
"nori_tokenizer": {
"type": "nori_tokenizer"
}
},
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["nori_readingform", "nori_part_of_speech"]
},
"ngram_analyzer": {
"type": "custom",
"tokenizer": "edge_ngram_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"standard": {
"type": "text",
"analyzer": "standard"
},
"nori": {
"type": "text",
"analyzer": "nori_analyzer"
},
"ngram": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
},
...
}
}
}'여기서 “nori_analyzer”와 “ngram_analyzer”를 동시에 정의해두어, 필드 name에서 name.nori와 name.ngram을 각각 다른 방식으로 분석할 수 있게 된다.
3.2 Document 매핑
@Document(indexName = "lost_item")
public class LostItemDocument {
@Id
private Long id;
// Nori + Edge NGram 적용
@MultiField(
mainField = @Field(type = FieldType.Text, analyzer = "standard"),
otherFields = {
@InnerField(suffix = "nori", type = FieldType.Text, analyzer = "nori_analyzer"),
@InnerField(suffix = "ngram", type = FieldType.Text, analyzer = "ngram_analyzer")
}
)
private String name;
// ...
}nori_analyzer와 nrgram_analyzer을 추가하고, suffix로 이 둘을 구분할 수 있도록 했다.
3.3 검색 로직
@Service
@RequiredArgsConstructor
public class LostItemSearchService {
private final ElasticsearchOperations elasticsearchOperations;
public SearchHits<LostItemDocument> searchLostItems(
// 날짜 범위, 키워드 등등...
) {
List<Query> mustQueries = new ArrayList<>();
List<Query> shouldQueries = new ArrayList<>();
// 1) 날짜 필터
// ...
// 2) 키워드 검색
if (hasKeyword) {
// Nori
shouldQueries.add(
MatchQuery.of(m -> m.field("name.nori").query(keyword))._toQuery()
);
// Edge NGram
shouldQueries.add(
MatchQuery.of(m -> m.field("name.ngram").query(keyword))._toQuery()
);
// Fuzzy
shouldQueries.add(
FuzzyQuery.of(f -> f.field("name").value(keyword).fuzziness("AUTO"))._toQuery()
);
}
// 3) 지역, 카테고리, 위치 필터
// ...
BoolQuery.Builder boolQueryBuilder = new BoolQuery.Builder().must(mustQueries);
if (hasKeyword) {
boolQueryBuilder.should(shouldQueries);
boolQueryBuilder.minimumShouldMatch("1"); // ★ 문제 원인
}
// 나머지 정렬/페이징
// ...
return elasticsearchOperations.search(searchQuery, LostItemDocument.class);
}
}이렇게 설정해두면 “강아지잠옷”에서 “강아지”, “잠옷” 두 가지 형태소가 추출되고, Edge n-gram이 “강아”, “강아지”, “강아지잠” 등으로 부분 검색을 지원해준다. 처음에는 이것만으로 “잠옷” 키워드도 제대로 검색이 가능해졌고, “강아지” 일부만 쳐도 찾을 수 있어 모든 문제가 해결된 줄 알았다.
4. 두 번째 문제: “강아지잠옷” 검색 시 “고양이잠옷”, “강아지지갑”도 검색됨
바로 여기서 새로운 문제가 발생했다.
- 검색어가 “강아지잠옷”일 때, "강아지잠옷"만 검색이 되어야 하는데,
- “강아지지갑”이 매칭: “강아지”라는 부분 토큰이 겹치기 때문에 결과에 포함
- “고양이잠옷”이 매칭: “잠옷”이라는 부분이 겹치기 때문에 결과에 포함
- 되는, 즉, 검색어가 길어졌을 때 “단어 전체"가 아니라 그 중 일부만 매칭돼도 결과로 나오는 문제를 발견하게 되었다.
원인은 BoolQuery에서 shouldQueries + minimumShouldMatch("1")를 써서, “강아지” 또는 “잠옷” 중 하나만 매칭되어도 조건을 만족하기 때문이었다.
4.1 문제 상황
| 검색어 | 검색 결과 | 의도치 않게 포함된 것 |
| 강아지잠옷 | 강아지잠옷, 고양이잠옷, 강아지지갑 | 봄이잠옷, 강아지지갑 |
| 강아지잠 | 강아지잠옷, 고양이잠옷, 강아지지갑 | 봄이잠옷, 강아지지갑 |
5. 해결: 토큰 분리 후 모두 must로 묶기
이 문제를 해결하기 위해, 키워드를 Nori Analyzer로 직접 토큰화한 뒤,
- 토큰이 여러 개일 때(예: “강아지잠” → [“강아지”, “잠”]) → 각 토큰을 전부 must로 추가하여 “강아지”와 “잠”을 동시에 포함하도록 했다.
- 토큰이 한 개일 때 → 기존처럼 should를 사용해 Fuzzy, n-gram 등을 적용하도록 했다.
아래 코드가 핵심 부분이다.
List<String> tokens = noriAnalyzerService.analyzeKeyword(keyword);
if (tokens.size() > 1) {
// 다중 토큰일 경우 각 토큰을 전부 must로 추가
for (String token : tokens) {
MatchQuery multiTokenMatch = MatchQuery.of(m -> m
.field("name.nori")
.query(token)
);
mustQueries.add(multiTokenMatch._toQuery());
}
} else {
// 단일 토큰일 경우 기존처럼 should에 추가
MatchQuery singleTokenMatch = MatchQuery.of(m -> m
.field("name.nori")
.query(keyword)
);
shouldQueries.add(singleTokenMatch._toQuery());
}그 다음에 위의 코드처럼 Edge n-gram, Fuzzy 등을 should에 추가한다.
BoolQuery.Builder boolQueryBuilder = new BoolQuery.Builder()
.must(mustQueries); // 필수 조건 추가
if (hasKeyword) {
boolQueryBuilder.should(shouldQueries);
boolQueryBuilder.minimumShouldMatch("1");
}이렇게 되면 “강아지”와 “잠”을 모두 갖고 있어야 한다”는 조건이 must로 걸려서, “강아지지갑”이나 “고양이잠옷”은 탈락하게 된다.
5.1 해결 결과
검색어 결과 의도하지 않은 것
| 검색어 | 결과 | 의도하지 않은 것 |
| 강아지잠 | 강아지잠옷 | |
| 강아지잠옷 | 강아지잠옷 | |
| 강아지 | 강아지잠옷, 강아지지갑 | 정상 (둘 다 “강아지” 포함) |
| 잠옷 | 고양이잠옷, 강아지잠옷 | 정상 (둘 다 “잠옷” 포함) |



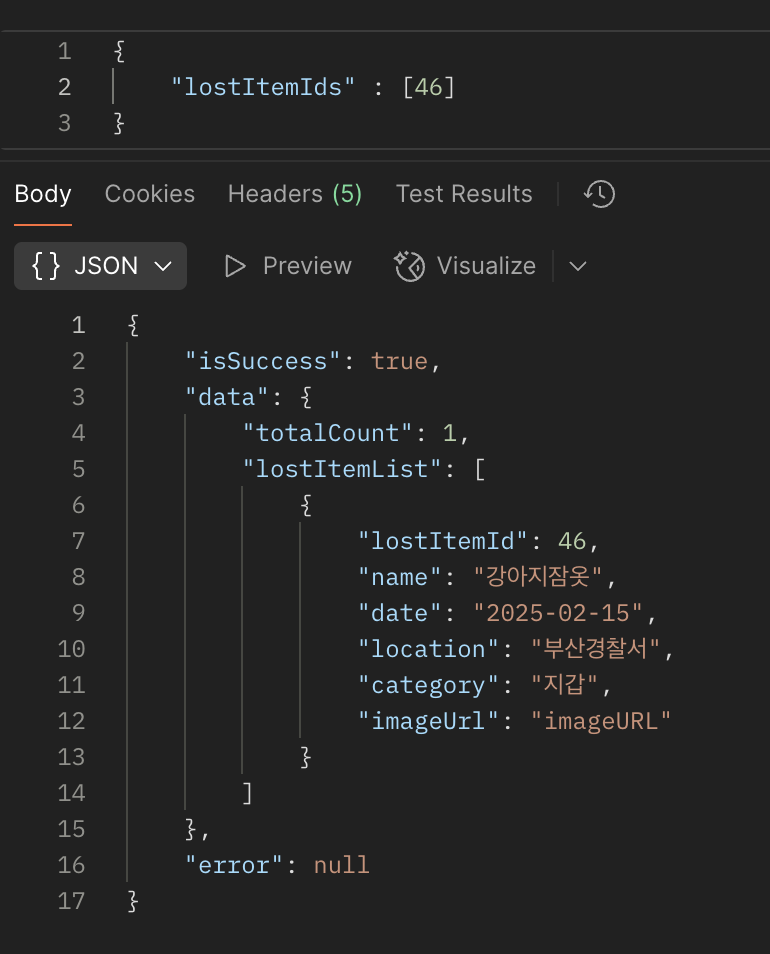
원하던 대로 “강아지잠옷” 검색 시 오직 “강아지잠옷”만 나오고, "고양이 잠옷"이나 “강아지지갑”은 제외된다!
7. 마무리
처음 생각했던 것과는 달리, 단순한 검색 설정(standard analyzer)만으로는 한국어 검색 품질을 보장할 수 없었다.
따라서 nori와 Edge n-gram을 적용해 부분 검색과 형태소 분석 문제를 해결했지만, 예상치 못한 과도한 검색 결과가 발생했다.
이를 보완하기 위해 토큰 개수를 분석하고 must 조건을 추가해 정확도를 높였고, 원하는 검색 결과만 반환할 수 있도록 개선했다.
이 과정을 통해 검색 품질을 높이는 것은 단순히 좋은 Analyzer를 선택하는 것이 아니라, 실제 서비스에서의 검색 패턴을 면밀히 분석하고 적절한 쿼리 구조를 설계하는 것이 핵심이라는 걸 배웠다. 앞으로도 검색 성능과 품질을 개선하기 위해 추가적인 최적화가 필요할 수도 있겠지만, 이번 개선을 통해 한 단계 더 발전한 검색 시스템을 구축할 수 있었기에 아주 유익했던 시간이었다!
'Spring' 카테고리의 다른 글
| [Elasticsearch 적용기] #1 Spring에서 Elasticsearch로 검색 성능 최적화하기 (1) | 2025.02.18 |
|---|---|
| [캡스톤 프로젝트] Spring Boot HTTPS로 배포하기 (0) | 2024.11.26 |
| [SPRING] Spring Data JPA로 동적 쿼리와 페이징 최적화하기: Specification과 @EntityGraph 활용 (1) | 2024.11.05 |
| [SPRING] Hibernate 지연 로딩으로 인한 JSON 직렬화 오류 해결하기 (0) | 2024.06.07 |
| [SPRING] 로깅에 AOP 적용해보기 (3) | 2024.06.01 |
- Total
- Today
- Yesterday
- SQLD
- 파이썬
- 백준
- 스프링 커뮤니티
- 자바 스프링
- 프론트엔드
- 지연로딩
- EnumType.ORDINAL
- 준영속
- 자바
- 웹 MVC
- 영속
- 회원탈퇴
- 인텔리제이
- 커뮤니티
- JPA
- 로깅
- elasticsearch
- SQL
- SQL 레벨업
- 스프링부트
- 웹MVC
- DP
- 다이나믹 프로그래밍
- 스프링 북마크
- 스프링
- 백준 파이썬
- 북마크
- 로그아웃
- 비영속
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |